< 목차 >
- 용어정의
- 요약
- 학습방법
- Edge Generator
- Image Completeion Network
- Edge Information & Image Mask
- Training Setup & Strategy
- 결과분석
- Qualitative Comparison
- Quantitative Comparison
- Ablation Study
- 결론
- 출처
1. 용어정의
- 피드백 후 작성예정입니다.
2. 요약
기존에 연구되었던 Inpainting 기술은 (1) Diffusion-based method, (2) Patch-based method 그리고 (3) Learning-based method 로 나뉘어져있고 각 방법들은 다음과 같이 간단히 설명할 수 있다.
(1) Diffusion-based method
- 삭제된 영역에 인접한 픽셀 값을 토대로 조금씩 채워나가는(Propagate) 형태로, 삭제영역이 큰 경우에 적용이 어렵다.
(2) Patch-based method
- 이미지 내에서 유사성이 가장 높은 영역을 찾아서 복사하는 형태로, 매번 Exhaustive search를 수행하여 연산의 복잡도가 상당히 높다. 즉, 계산시간이 오래 걸린다.
(3) Learning-based method
- Adversarial model 을 기반하여 Image와 Mask를 통해 Generator 를 학습시켜 삭제된 영역의 영상을 복원하지만, 품질이 over-smoothed 되거나 비정상적으로 복원되는 경우가 많다.
이러한 Inpainting 기술은 영상의 디테일을 표현하는데 한계가 있었고, 논문의 저자는 실제로 그림을 그릴 때 선을 먼저 긋고 색을 입히는 "Line First, Color Next"의 개념을 착안하여 이러한 한계를 개선하고자 했다.
논문에서 연구된 Inpainting 모델은 Two-stage process 를 따르며, 여기서 기여한 점은 크게 세 가지이다.
(1) 이미지에서 삭제된 영역의 선을 생성하는 Edge Generator 의 도입
(2) 생성된 Edge 에 색(Color)과 질감(Texture)를 칠하는 Image Completion Network의 연계
(3) 앞서 소개된 두 가지 네트워크의 End-to-End Training
3. 학습방법
소개된 Two-stage process model 은 한 쌍의 Generator, Discriminator로 구성된 Edge Generator 와 또 다른 한 쌍의 Generator, Discriminator로 구성된 Image Completion Network 로 이루어진다. 이때, 저자는 각각의 Generator와 Discriminator를 G1, D1 와 G2, D2라고 정의하였다.
여기서 G의 아키텍처는 두번의 down-sample을 수행하고 8 개의 residual blocks인 Encoder 와 다시 기존 이미지의 크기로 복원하는 Decoder 로 구현되어있고 일반적인 콘볼루션을 사용하지 않고 dilation 크기가 2인 2-Dilated Convolution을 사용하여 연산을 하고, D의 아키텍처는 "Image-to-Image Translation with Conditional Adversarial Networks"에서 소개된 70 x 70 PatchGAN을 사용하였다.
따라서, 본 논문에서 소개된 EdgeConnect 의 아키텍처 전체 구조는 아래와 같다.

3-1. Edge Generator
Edge Generator 에 대한 수학적 모델은 다음과 같이 설명할 수 있다.
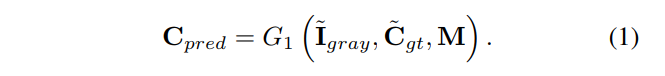
Edge Generator는 Gray scale의 마스킹된 이미지, 상응하는 Edge map 그리고 해당 Mask를 입력받아 삭제된 영역에 대한 Edge map 을 생성할 수 있다.


이때, 원본이미지는 I_gt, 원본이미지에 상응하는 Edge map은 C_gt, Gray scale 이미지는 I_gray 로 정의하면, Gray scale의 마스킹된 이미지, 상응하는 Edge map 는 이와 같이 표현된다.
이로써, 원본이미지에 대한 Edge map(C_gt) 와 Edge Generator 를 통해 생성된 새로운 Edge map를 획득할 수 있고, Generator-Discriminator는 Adversarial Loss(L_adv)와 Feature-Matching Loss(L_FM)를 통해 학습한다.

해당 수식에서 Lambda는 실험에 의해 각각 L_adv = 1, L_FM = 10으로 지정되었으며, Regularization 역할을 수행한다.

이때, Edge Generator 학습을 위한 Adversarial Loss(L_adv)는 위의 수식으로 나타낼 수 있고, 이는 GAN에서 소개된 기본적인 Loss 함수와 같다. 즉, Discriminator(D1)이 Real 와 Predicted data 를 구분할 수 있는 능력이 최대(max)가 되게끔하고 Generator(G1)은 이것을 최소화(min)하는 것을 목표로 Loss 값이 수렴되도록 한다.

Feature-Matching Loss(L_FM) 또한, 위의 수식으로 나타낼 수 있고 D1을 구성하는 Hidden Layer에서 원본이지지에 대한 Edge map(C_gt)와 생성된 Edge map(C_pred)에 대한 Activation map을 비교한다. 이때, L 은 D1의 Hidden Layer의 수이며, N_i는 i번째 Layer에서의 Activation map의 수이다.
이 L_FM은 G1이 원본이미지와 유사한 이미지를 생성할 수 있도록 만들어 Adversarial한 학습 프로세스를 안정화 시키는 역할을 한다. 이론상으로는 가장 큰 특이값(Singular value)을 통해 네트워크의 Weights을 scaling down 하는 방법인 Spectral Normalization(SN)을 도입하면 더욱 학습 프로세스를 안정화 시킬 수 있다고 소개되어 있으나 본 논문에서는 학습시간이 너무나 느려지기 때문에 사용하지 않았다고 한다.
3-2. Image Completion Network
Image Completion Network 에 대한 수학적 모델은 다음과 같이 설명할 수 있다.

Image Completion Network는 마스킹된 이미지(I~gt)와 생성된 Edge map(삭제영역에서 생성된 Edge와 기존의 Edge가 결합된, C_comp)을 입력받아 최종적으로 Inpainted 된 이미지를 출력할 수 있다.


마스킹된 이미지는 I~gt, 새로 생성된 영역의 Edge(C_pred)와 기존 영역 Edge(C_gt)과 결합된 Edge map은 C_comp 로 표현된다.

Image Completion Network는 네 가지의 Loss 함수가 구성된 Joint Loss 를 사용하며, 이는 각각 L1 Loss, Adversarial Loss, Perceptual Loss, Style Loss 이다. 이때, 각 Loss의 Lambda는 l1 = 1, adv = perc = 0.1, style = 250 로 설정되었다. 이 중 L1 Loss는 간단하게 Ground Truth인 원본이미지와 생성된 이미지의 차이를 Pixel 별로 비교하는 방식으로, 마스크 크기(삭제영역 크기)에 대해 정규화를 수행하여 계산한다.

Perceptual Loss (L_perc)는 Pre-trained model을 통해 이미지를 인식하고 라벨링하는데, 이때 원본이미지와 생성이미지의 Hidden Layer들의 Activation map의 distance를 비교하면서 유사하지 않은 생성이미지에 패널티를 부과하는 역할을 한다. (L_adv,2 는 앞서 소개된 Adversarial Loss 와 동일한 "G2"에 관한 수식으로 설명은 생략) 또한, 논문에서는 ImageNet dataset을 학습한 Pre-trained 된 VGG-19 모델을 사용하였으며, Activation map을 Loss를 계산하는데 relu1_1, relu2_1, relu3_1, relu4_1, relu5_1 레이어의 Activation map을 사용하였다.

위의 Perceptual Loss에서 사용된 Activation map들은 Style Loss에도 사용되었으며, 이는 각 레이어의 map들로부터 Gram matrix를 구하고 원본이미지와 생성이미지간 차이를 최소화하는 역할을 한다.
이 Style Loss 는 "EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis" 에서 처음 도입되었고, Learning-based method의 고질적인 영상품질 문제였던 blurriness 나 checkerboard artifacts를 비교적 효과적으로 방지할 수 있다고 소개되었다. (아래는 Style Loss 역할을 확인할 수 있는 생성이미지 비교사진이다. )

3-3. Edge Information & Image mask
본 논문에서는 Edge Generator인 G1을 학습하기 위해 Canny Edge Detector 를 사용하여 Edge maps을 생성하였고, 이때 Edge Detector의 민감도를 제어하는 Gaussian Smoothing Filter의 Standard deviation 값을 "2"로 설정하였다. 필터의 파라매터를 "2"로 설정한 이유는 여러 실험을 통해 최적값이라는 결론이 도출되었으며, 근거는 아래와 같이 소개되었다. (PSNR과 FID는 영상품질에 대한 정량적 지표로서, PSNR 은 높을수록 FID는 낮을수록 좋다. 즉, Sigma 값이 2일때가 가장 적합하다고 한다.)

Image masks는 두 가지 유형으로 나눠 학습했는데 (1) 이미지크기의 25% 정도 차지하는 사각형태의 마스크이며 랜덤하게 위치하여 학습에 사용하였고,(2) "Image Inpainting for Irregular Holes Using Partial Convolutions"에서 제공된 불규칙한 마스크 데이터셋을 rotation, horizontal reflection 방식으로 증대시켜 학습에 사용하였다.
3-4. Training Setup & Strategy
PyTorch로 모델을 구현하였으며, 256 x 256 픽셀 크기의 8개 묶음(Batch) 이미지를 모델 학습에 사용하였다. 모델은 Adam optimization로 Loss를 최소화하였고, 이때 Adam optimizer 파라미터는 B1 = 0, B2 = 0.9 으로 설정되었다.
G1과 G2 모델은 Canny Edge를 사용하였으며, Loss가 더이상 감소하지 않는 지점까지 1e-4 의 Learning rate로 각각 학습하고, 이후부터는 1-e5의 Learning rate로 Loss가 수렴할 때까지 학습한다. D1과 D2 모델은 각각 G1과 G2의 1/10의 Learning rate로 학습하며, 마지막에는 모델에서 중간 D1을 제거하고 1e-6의 Learning rate로 전체 모델을 fine-tune한다. (End-to-End Training)
4. 결과분석
논문에서 소개된 Model은 CelebA, Places2, Paris StreetView dataset을 통해 학습하고 기존의 state-of-the-art 기술과 비교 및 평가되었다.
4-1. Qualitative Comparison
정성적 기준에서, 저자는 Details이 삭제된 영역에서도 Checkerboard artifacts 나 Blurriness가 없는 "Photo-Realistic" 한 결과를 내었다고 소개하고 있다.
4-2. Quantitative Comparison
정량적 기준에서, Numeric 과 Visual Turing의 두 가지 유형으로 영상품질을 수치적으로 나타내었다.
4-2-1. Numerical Metrics
본 논문에서는 영상품질을 계산하는 지표로 (1) relative L1, (2) Structural Similarity Index (SSIM), (3) Peak Signal-to-Noise Ratio (PSNR), (4) Frechet Inception Distance (FID) 를 사용하였다.
이때, (1) L1, (2) SSIM, (3) PSNR은 pixel 단위로 계산되기 때문에 전체적으로 볼때는 실제와 다른 결과물에 대해서도 나름 괜찮은(Favorable) 스코어를 계산할 가능성이 있다. 이 때문에, 이미지에 대한 모델의 전체적인 인식률을 나타내는 지표로 FID를 추가하였다. FID 에 대해 추가설명하자면, 실제 원본이미지와 생성이미지의 Feature Space 간의 Wasserstein-2 Distance를 계산한 것으로 Pre-trained Inception-V3 model을 인식에 이용하고 각 Feature space를 계산한다.

각 지표에 대한 정량적 수치는 아래의 테이블에 있으며, L1과 FID는 낮을수록 좋고, SSIM과 PSNR는 높을수록 좋다. 이때, L1에 대해서는 PConv 모델이 더 좋은 것으로 나오는데, 논문에서는 이러한 이유가 L1 계산방식의 차이에서 기인한 것이라고 추측하고 있다.
4-2-2. Visual Turing Test
또한 Visual Turing Test로 Human Perception 까지 고려하였는데, 이때의 방법으로 2-Alternative Force Choice(2AFC) 와 Just Noticeable Differences(JND)를 사용하였다.
- 2AFC : 지원자에게 랜덤하게 샘플링된 이미지로부터 각 이미지가 실제이미지인지 생성이미지인지 선택하게 하고 스코어를 가산하는 방식
- JND: 실제이미지와 생성이미지 쌍으로부터 어느것이 더 진짜같은지 고르게 하는 방식
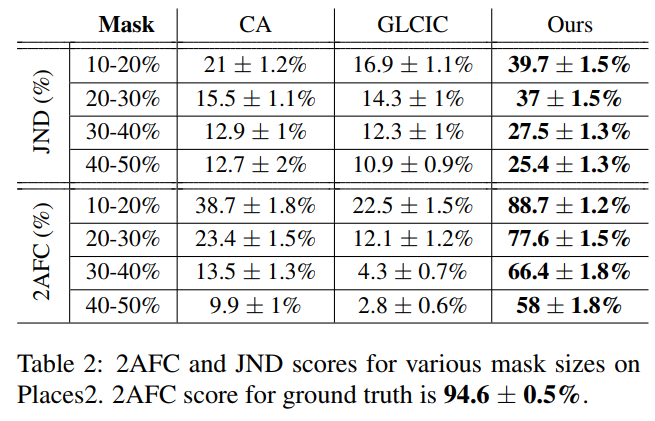
각 이미지를 선택하는데 지원자에게는 2초의 시간만 주어지며, 이미지당 10번 반복하였으며 총 300장의 이미지샘플을 통해 스코어를 계산하였다. 결과는 아래와 같으며, 실제이미지에 대한 2AFC는 대략 94.6 % 에 0.5% 오차를 갖고있다.
4-3. Ablation Study
Ablation Study 는 의학실험에서 사용되는 용어로, 생물을 구성하는 각 기관의 역할을 확인하기 위해 해당 기관을 제거한 후의 결과를 보는 것이다. 같은 선상에서 바라보면 Machine Learning 분야에서는 Ablation Study 라는 용어가 구축된 네트워크에서 특정부분이 기여하는 역할을 확인하기 위해 해당 부분을 제거하고 결과물을 보는 것이다.
본 논문에서는 2-Stage process 네트워크 모델의 Edge Generator가 (1) 과연 Image Completion에 도움을 주는지, (2) 그렇다면 어느정도만큼 Edge map이 필요한지 보기위해 Ablation Study를 진행하였다. 아래 테이블에서 볼 수 있듯이, Edge Generator가 있을 경우(Yes) 가 Edge Generator가 없을 경우(No) 보다 네 가지 지표에서 결과가 개선되었음을 알 수 있다.

또한, Canny Edge Detector를 통해 Edge map을 생성할 경우에 Gaussian Smoothing Filter 의 Standard Deviation 값이 너무 낮을 경우 과도하게 Edge가 생성되어 Image Completion에 부정적인 결과를 초래할 수 있고 너무 높은 경우에는 Edge가 적게 생성되어 실제와 근사한 이미지 생성이 어려울 수 있다.

5. 결론
본 논문에서는 "Line First, Color Next" 의 개념을 착안하여 Edge Generator-to-Image Completion 의 2-Stage Network를 소개하였다. 삭제된 영역에 Edge 생성의 선행은 생성된 영상품질 개선에 기여한다는 점이 실험을 통해 증명되었고, 이러한 모델은 삭제된 영역에 있는 세부적인 디테일까지도 묘사할 수 있다.
따라서, 소개된 Inpainting 모델은 (1) Restoration, (2) Removal, (3) Synthesis 의 세 가지 영역에 적용될 수 있는데, 그 중 Removal와 Synthesis에 적용한 결과물만 놓고 봤을 때는 기존 Inpainting 기술에 비해 영상품질이 상당히 우수하다.
아래는 모델의 Application 사례이다.


6. 출처
- EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning - arxiv.org/abs/1901.00212
- Image-to-Image Translation with Conditional Adversarial Networks - arxiv.org/abs/1611.07004
- EnhanceNet: Single Image Super-Resolution Through Automated Texture Synthesis - arxiv.org/abs/1612.07919
- Image Inpainting for Irregular Holes Using Partial Convolutions - arxiv.org/abs/1804.07723
'인공지능 > 컴퓨터비전' 카테고리의 다른 글
| Convolution Neural Networks & Visualization (0) | 2021.04.21 |
|---|---|
| Loss functions for Image Transformation (1) | 2021.04.20 |
| Partial Convolution based Padding (0) | 2021.04.19 |
| Image Inpainting for Irregular Holes Using Partial Convolutions (0) | 2021.04.16 |
| Deep Convolutional Generative Adversarial Nets(DCGANs) (0) | 2021.04.14 |



