< 목차 >
- 용어정의
- 요약
- Convolutional Neural Network
- Filter & Kernel
- Understanding Edge Detection of Filters
- Layer
- Padding
- Stride
- Backpropagation
- Visualization of CNN
- Filters
- Feature maps
- 결론
- 출처
1. 용어정의
- 피드백 후 작성예정입니다.
2. 요약
일반적으로 인간은 어떤 사물을 인지할 때, 사물의 전체적인 모양을 보고 천천히 디테일한 부분까지 살펴본다. 뉴럴네트워크에서는 다층 레이어(Layer)를 통해 이 인지과정을 모방하였으며, 앞부분의 레이어는 선을 인식하고, 점점 레이어가 깊어질수록, 선을 면으로, 면을 사물의 전체적 구조로, 그리고 특징적 부분으로 확장시켜 사물을 인지하는 과정을 거친다.
이는 레이어가 깊어질수록 Feature map 이 표현할 수 있는 영역(Receptive Field)의 범위가 증가하기 때문인데, 본문에서는 CNN의 내부구성을 살펴보고 각 레이어별 Filter와 Feature map을 시각화하여 실제로 그러한지 코드를 구현하여 확인해보았다.
3. Convolutional Neural Network
3-1. Filter & Kernel
필터(혹은 커널)와 콘볼루션 연산을 이용해서 이미지 내 존재하는 객체를 파악하는 모델을 Convolutional Neural Network(CNN) 라고 하며, 콘볼루션 연산을 통해 이미지 전체를 슬라이딩하며 출력값을 계산한다. 보통 입력이미지는 RGB의 경우 3개의 채널을 가지며 각각 R, G, B를 의미하며, Grayscale의 경우 1개 채널을 가진다. 이때, 콘볼루션 연산을 통해 출력된 값은 각 연산에 포함된 계산값의 합으로 아래와 같은 애니메이션으로 이해하기 쉽게 표현될 수 있다.

여기서는 3개의 채널을 가지는, 0으로 패딩된 7 x 7 크기의 입력이미지와 3개의 채널과 3x3 크기를 가지는 필터 W0, W1 를 통해 Stride 크기가 2인 콘볼루션 연산하고, 채널크기가 2인 3 x 3 크기의 출력 매트릭스를 계산하는 과정이다. 이때, 입력이미지의 채널크기와 연산을 수행하는 필터의 채널크기는 반드시 동일해야하고, 필터의 수는 출력 매트릭스의 채널크기와 동일하다.
3-2. Understanding Edge Detection of Filters
CNN 의 각 레이어에서 콘볼루션 연산을 통해 이미지 내 객체의 선을 찾아내는 과정을 살펴보기 위해, 콘볼루션 연산을 통한 엣지 검출을 예로 들수 있다. 왼쪽면이 밝고 오른쪽면이 어두운 입력이미지와 엣지검출에 사용되는 3 x 3 필터를 콘볼루션 연산했을 경우, 아래 사진의 오른쪽과 같은 매트릭스가 계산된다.

이 매트릭스를 이미지형태로 출력했을 경우, 밝은 면과 어두운 면을 기준으로 한 선에 대해서 높은 밝기값을 나타내고 있음을 알 수 있다. 마찬가지로, 수평 엣지에 대해서도 동일하게 검출할 수 있으므로, CNN은 콘볼루션 연산을 통해 입력이미지 내 존재하는 사물의 엣지를 인식할 수 있게 되며, 이를 확장해서 특징적인 부분 또한 인식할 수 있게 된다
3-3. Layer
CNN은 크게 4가지 타입의 레이어들로 구성되는데, (1) Convolutional Layer, (2) Non-linearity, (3) Pooling Layer, (4) Fully-connected Layer 가 그것이다.
(1) Convolution Layer
- 콘볼루션 연산을 수행하는 레이어이며, 필터에 대한 정보를 가지고 있고 Backpropagation을 통해 학습한다.
(2) Non-linearity
- Convolution Layer 뒤에는 non-linearity layer 가 존재하며, 주로 Rectified Linear Units(ReLU)을 Activation function으로 사용한다.
(3) Pooling Layer
- 이미지 혹은 연산 매트릭스의 크기를 축소하는 레이어로 다음 레이어에서 변수크기를 감소시켜준다. 이론상으로는 average-pooling 방법이 모든 픽셀값을 고려하여 가장 좋은 것처럼 보이나 실제로는 max-pooling이 더 좋은 성능을 나타낸다고 한다
(4) Fully-connected Layer
- CNN 의 끝부분에 위치한 레이어로, 콘볼루션 연산된 매트릭스를 벡터화하여 softmax activation function을 통해 상응하는 라벨에 분류될 확률 값을 계산한다
3-4. Padding
이미지의 엣지나 코너는 중앙에 비해 CNNs 성능에 크게 영향을 미치지않는다는 연구로부터, 원하는 크기의 출력이미지를 연산하기 위해 Padding기법이 도입되었고 보통 zero-padding을 주로 사용한다.
3-5. Stride
콘볼루션 연산에서 필터가 이미지 매트릭스를 슬라이딩할 때 매 연산마다 건너뛰는 크기를 말하며, Stride 크기가 커질수록 출력 매트릭스 크기는 작아진다. Convolution Layer 에서는 앞에서 언급한 Filter, Padding, Stride 등의 크기에 따라 출력 매트릭스의 크기를 계산하는 공식이 있고 수식은 아래와 같다.

3-6. Backpropagation
CNN을 포함한 대부분의 네트워크는 Backpropagation 방법을 통해 모델의 파라매터들을 학습시킨다. 모델의 출력값과 라벨링된 타겟값를 비교한 Loss 함수를 최소화하기 위해서 일반적으로 Gradient Descent 최적화방법을 사용하여 필터를 포함한 모델의 파라매터 값들을 변경하며, 이때 Chain rule을 통해 최적의 변경값을 갱신한다.

4. Visualization of CNN
앞서 기술한 내용을 통해, Pre-trained 된 네트워크 모델의 필터와 특징맵에 관한 정보를 시각화하여, 확인할 수 있는 정보는 아래와 같다.
- Filter: 엣지를 검출하는 필터들이 어떤 정보를 담고 있는가?
- Feature map: 주어진 입력이미지로부터, 각 레이어는 실제로 엣지를 검출하는가?
4-1. Filter
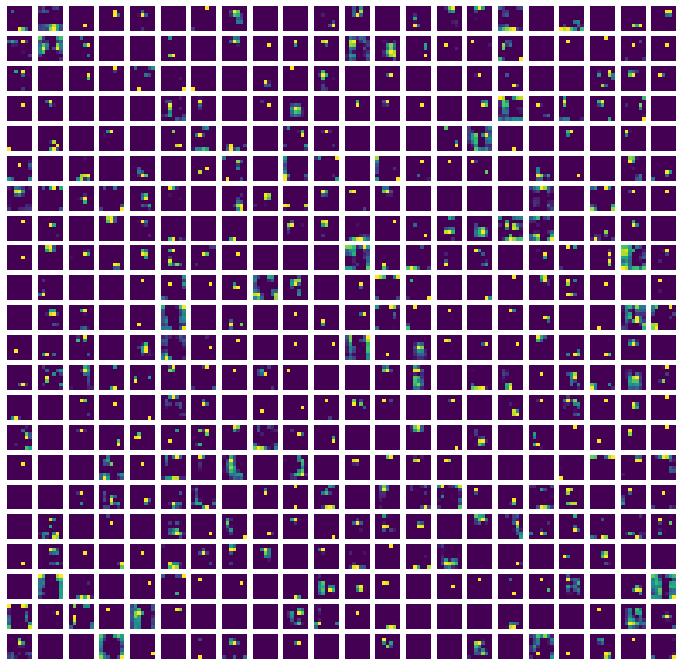
구현을 위한 필터 시각화는 Alexnet 모델을 사용하였는데, 이는 pre-trained 모델 중에서 비교적 간단하고 맨앞에 위치한 Convolution Layer 필터크기가 11 x 11로 시각화에 효과적이기 때문이다. 엣지 부분을 인지하는 제일 처음에 위치한 Convolution Layer의 필터를 추출하여 시각화한 결과는 다음과 같다.

위에서 본 엣지검출 필터와 비슷하게 필터들이 패턴형을 띄고 있다. 이러한 필터들이 콘볼루션 연산을 통해 엣지부분을 밝게 혹은 어둡게 검출해낼 수 있다. 업로드된 구현코드에서 Alexnet이 아닌 VGG16 등의 모델을 로드하여 Filter의 가중치를 확인할 수 있다.
4-2. Feature map
또한 VGG16 모델을 로드하여, 샘플이미지가 모델의 각 레이어를 통과하면서 출력되는 특징맵(Feature map) 을 확인할 수 있는데 Convolution Layer의 어느위치에서 엣지가 검출되는지 확인할 수 있다.

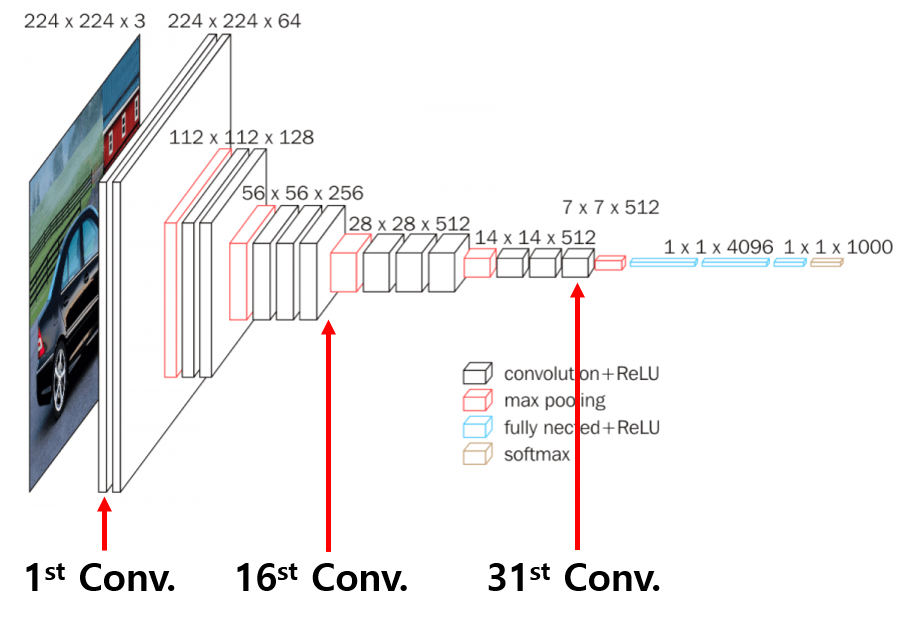
VGG16 모델구조에서 표시된 바와 같이 맨 앞, 중간, 그리고 맨 끝에 위치한 위치한 Convolution Layer로부터 연산된 특징맵을 아래와 같이 출력할 수 있었다.


각 레이어에서의 특징맵 개수는 해당레이어에서의 필터 수와 같으며, 첫번째 레이어에서는 각 필터의 연산에 따라 엣지가 검출되는 것을 확인할 수 있다. 레이어가 점점 깊어질수록 엣지를 구분하는 기준을 인식하기 때문에 디테일해지는 것을 확인할 수 있다.
위에서 보이는 것처럼 각 레이어별로 특징맵의 개수는 무수하며, 각 레이어를 대표하는 특징맵을 단수로 시각화하여 네트워크를 구성하는 모든 레이어에 대해 샘플이미지가 어떻게 처리되는지 확인하기 위해서 모든 특징맵에 대해 평균하여 시각화할 수 있다.

5. 결론
직접 내부 레이어에 대한 필터와 특징맵을 시각화해보니 CNN 내부에서 입력데이터의 처리흐름을 이해할 수 있으며, CNN 내부를 구성하고 있는 각 기능들이 어떠한 역할하는지 확인할 수 있었다. 또한, ResNet, VGG 등과 같은 Pretrained 모델의 특징맵을 추출해서(hooking 이라고도 함) Gram matrix 등과 같은 Loss 연산에도 사용할 수 있으니 한번쯤은 모델별로 해체해서 내부를 시각화해보는 것도 CNN을 이해하는데 도움이 될 것이라 생각한다.
(관련코드는 모두 코드구현카테고리 에 업로드할 예정이니 참고하면 좋을 것 같습니다.)
6. 출처
- cs231n.github.io/convolutional-networks/ - CS231n Convolutional Neural Networks for Visual Recognition
- m.blog.naver.com/PostView.nhn?blogId=infoefficien&logNo=221132998535&proxyReferer=https:%2F%2Fwww.google.com%2F - 3. More Edge Detection
- www.youtube.com/watch?v=dKu911Zveb0 - Neural Networks 11: Backpropagation in detail
'인공지능 > 컴퓨터비전' 카테고리의 다른 글
| Content & Style Extraction (4) | 2021.04.26 |
|---|---|
| Visual Interpretability for Convolutional Neural Networks (2) | 2021.04.22 |
| Loss functions for Image Transformation (1) | 2021.04.20 |
| EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning (0) | 2021.04.19 |
| Partial Convolution based Padding (0) | 2021.04.19 |



