< 목차 >
- 용어정의
- 요약
- Perceptual Loss Functions
- Feature Reconstruction Loss
- Style Reconstruction Loss
- Simple Loss Functions
- Pixel Loss
- Total Variation Regulation
- 결과분석
- 결론
- 출처
1. 용어정의
- 피드백 후 작성예정입니다.
2. 요약
컴퓨터비전(Computer Vision)과 영상처리(Image Processing)에는 Image Transformation이 필수적이며, 일반적으로 딥러닝 모델을 이용한 Transformation은 (1) Per-pixel Loss 와 (2) Perceptual Loss 를 최적화하는 방법을 이용하여 모델을 학습시킬 수 있다.

이때 각각의 Loss Function 을 이용한 방법의 특징은 아래와 같다.
(1) Per-pixel Loss
- 원본이미지와 네트워크 모델의 출력이미지의 차이를 각 픽셀 값별로 비교한 것으로, Iteration 없이 한번의 Forward pass만 필요하며 Inference 시 속도가 빠르다. 하지만, 이미지 전체에 대한 인식이 고려되지 않아서 동일한 이미지가 1 픽셀만이라도 움직인다면, 다른 이미지로 판단하여 신뢰도가 낮다.
(2) Perceptual Loss
- (Pre-trained 된) 네트워크 모델의 Hidden Layers에서 원본이미지와 입력이미지의 Feature Space 간의 차이를 비교하는 것으로, 높은 수준의 결과를 출력할 수 있지만 Inference에서도 Feature Space 간의 연산이 필요하기 때문에 속도가 느리다.
근래 연구는 이러한 두 가지 유형의 Loss Functions 을 결합하여, 각각의 장점만 살린 Joint Loss Function이 많이 사용되고 있고, 이 부분에 대해 이해한 내용을 바탕으로 자료를 작성하고자 한다.
3. Perceptual Loss Functions

상기의 아키텍처는 "Perceptual Losses for Real-Time Style Transfer and Super-Resolution" 에서 제안되었으며, Perceptual Loss를 기존 Per-pixels Loss 에 결합하기 위한 구조이다.
기본적인 원리는 원본이미지셋으로 훈련된 Image Transform Net(임의의 네트워크)를 통해 출력이미(Y_hat)를 계산하고, 이것과 원본이미지를 함께 Pre-trained 된 네트워크 모델(여기선 VGG-16 이지만, VGG-19, Alexnet 등 사용가능함)로 입력하여 Hidden Layer(relu1_2, relu2_2, relu3_3, relu4_3)에서의 Feature space (map)을 추출하여 해당 특징을 비교하는 것이다.
이렇게 하는 이유는 이미 학습된 이미지 분류모델이 각 이미지에 대해 적절한 Feature Map을 갖고 있기 때문인데, 결국엔 Image Transform Net의 Loss 연산을 위해 훈련되지 않는 고정형 네트워크가 하나 더 추가되는 셈이다.
3-1. Feature Reconstruction Loss
Feature reconstruction loss는 Pre-trained 모델 Hidden Layers에서 출력이미지와 원본이미지의 두 Feature space 을 추출하여 연산하며, 두 Feature space 간의 Euclidean distance를 나타낸다. 해당 Loss의 특징은 아래 그림과 같이 이미지 전반적인 구조(Overall spatial structure)를 유지하며, 그 외 색상이나 질감에 대한 특징은 보존하지 않는다.

이러한 이유는 Pre-trained 된 네트워크 모델의 뒷부분으로 갈수록 대략적인 Edge로부터 구체적인 패턴으로 Feature를 추출할 수 있는데, 때문에 이미지 상의 전반적인 구조를 표현하는 특징을 추출하기 위해 뒷 단 Hidden Layer 의 출력값을 하나만 사용한다.
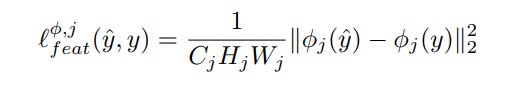
여기서 Φ은 Hidden Layer의 Feature map이며, j는 Hidden Layer의 깊이를 말한다. 또한, C, H, W는 각각 연산된 Feature map의 채널, 높이, 폭을 일컫는다. 해당 수식에서는 출력이미지와 원본이미지 Feature의 차이를 L2 norm(Frobenius norm, Euclidean norm이라고도 함)으로 나타내고, Feature number(C*H*W)로 정규화한다.
3-2. Style Reconstruction Loss
Style reconstruction loss는 바로 위에 설명했던 Feature reconstruction loss와 정반대로, 이미지의 전반적인 구조보다는 원본이미지의 색상이나 질감을 출력이미지가 표현할 수 있도록 만드는데 기여하는 Loss 이다.

Style은 색상, 질감, 형태 등 다양한 내용들을 포함하기 때문에, 여러 개의 Hidden Layer에서 Feature를 추출하며, 이것을 내적하여 Gram matrix라는 것으로 만들어서 Euclidean distance를 비교하는데, 이렇게 Gram matrix로 연산하는 이유는 각 Layer를 내적하면 Layer 간의 Correlation 정보를 갖고 있기 때문에 그러한 정보가 이미지가 갖고 있는 복합적인 스타일을 표현할 수 있다. 따라서, Style reconstruction loss 는 각 Layer간의 Correlation을 보존하며 이미지의 구조가 변화하는 역할을 수행할 수 있다.

여기서 Φ은 Hidden Layer Hidden Layer의 Feature map이며, j는 Hidden Layer의 깊이를 말한다. 또한, C, H, W 는 각 Feature map의 채널, 높이, 폭이며, 해당 Layer에서의 Feature map간 내적하고 C*H*W로 정규화하여 구할 수 있다. 이때, Gram matrix는 Feature map을 C x (H*W) 크기로 배열을 변환하여 계산할 수 있으며, 계산 후 크기는 C x C 가 된다.

마지막으로, 입력이미지와 원본이미지 간의 Feature map으로 구한 Gram matrix 끼리 비교하기 위해 Euclidean distance를 계산하며 이것을 Style Loss 로 정의한다.
4. Simple Loss Functions
Simple Loss 는 (1) Pixel Loss와 (2) Total Variation Regularization 두 가지 유형으로 나뉜다.
4-1. Pixel Loss
Pixel Loss는 출력이미지와 원본이미지 간의 Euclidean distance를 비교하는 것으로 픽셀 간 비교하는 것으로 볼 수 있으며 수식은 아래와 같다.
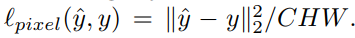
y_hat은 출력이미지, y는 원본이미지를 가르키며, C, H, W는 이미지의 채널, 높이 ,폭으로서 출력와 원본이미지의 크기는 동일하다.
4-2. Total Variation Regularization
Total Variation Regularization은 출력이미지에서 인접한 주위 픽셀 값들의 연속성이 보전되더야 하기 때문에, 인접 값들의 차이가 크기 않도록 이미지를 smoothing 해주는 역할을 한다.

I_comp 는 삭제된 영역에는 생성된 이미지를, 삭제되지 않은 영역은 원본이미지의 값들을 결합한 것이며, N는 픽셀 수이다.
5. 결과분석
본 논문에서는 앞서 소개된 Loss들을 아래와 같이 결합하여 Style Transfer 를 이용한 새로운 이미지 생성에 대한 연구를 하였다. Perceptual Loss를 연산하기 위해 VGG-16 네트워크 보멜을 사용하였고, Feature Loss는 relu2_2, Style Loss 는 relu1_2, relu2_2, relu3_3, relu4_3 에서 추출하여 Loss를 연산하였다.

해당 Loss를 이용하여 이미지를 생성한 결과는 다음과 같다.

6. 결론
이 논문의 저자는 Per-pixel Loss가 아닌 새로운 개념의 Perceptual Loss를 도입하였다. 이 Loss 연산을 위해서는 객체인식(주로 Classification)목적으로 학습되었던 네트워크 모델에서 Feature map 추출이 필요하며, 주로 VGG-16이나 VGG-19 모델이 사용된다. Image Inpainting 기술뿐만 아니라 Image Completion 에 직접적으로 사용되는 Loss 로써, 연산원리를 이해할 필요가 있다.
위 논문에서 소개된대로 Perceptual Loss 를 활용한 Style Transfer 를 Pytorch기반으로 간단히 구현해보았다.






7. 출처
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution - arxiv.org/abs/1603.08155
- Image Inpainting for Irregular Holes Using Partial Convolutions - arxiv.org/abs/1804.07723
- A Neural Algorithm of Artistic Style - arxiv.org/abs/1508.06576
- Texture Synthesis Using Convolutional Neural Networks - arxiv.org/abs/1505.07376
'인공지능 > 컴퓨터비전' 카테고리의 다른 글
| Visual Interpretability for Convolutional Neural Networks (2) | 2021.04.22 |
|---|---|
| Convolution Neural Networks & Visualization (0) | 2021.04.21 |
| EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning (0) | 2021.04.19 |
| Partial Convolution based Padding (0) | 2021.04.19 |
| Image Inpainting for Irregular Holes Using Partial Convolutions (0) | 2021.04.16 |



