< 목차 >
- 용어정의
- 요약
- 특징 추출방법
- 분석결과
- 출처
1. 용어정의
- 피드백 후 작성예정입니다.
2. 요약
본 내용에서는 학습된 네트워크 모델(VGG, ResNet 등)과 Loss functions을 이용해서 레이어 내부로부터 어떤 특징을 추출하고 활용할 수 있는지 확인할 수 있다. (해당코드는 코드구현 카테고리에 업로드 예정입니다.)
3. 특징 추출방법
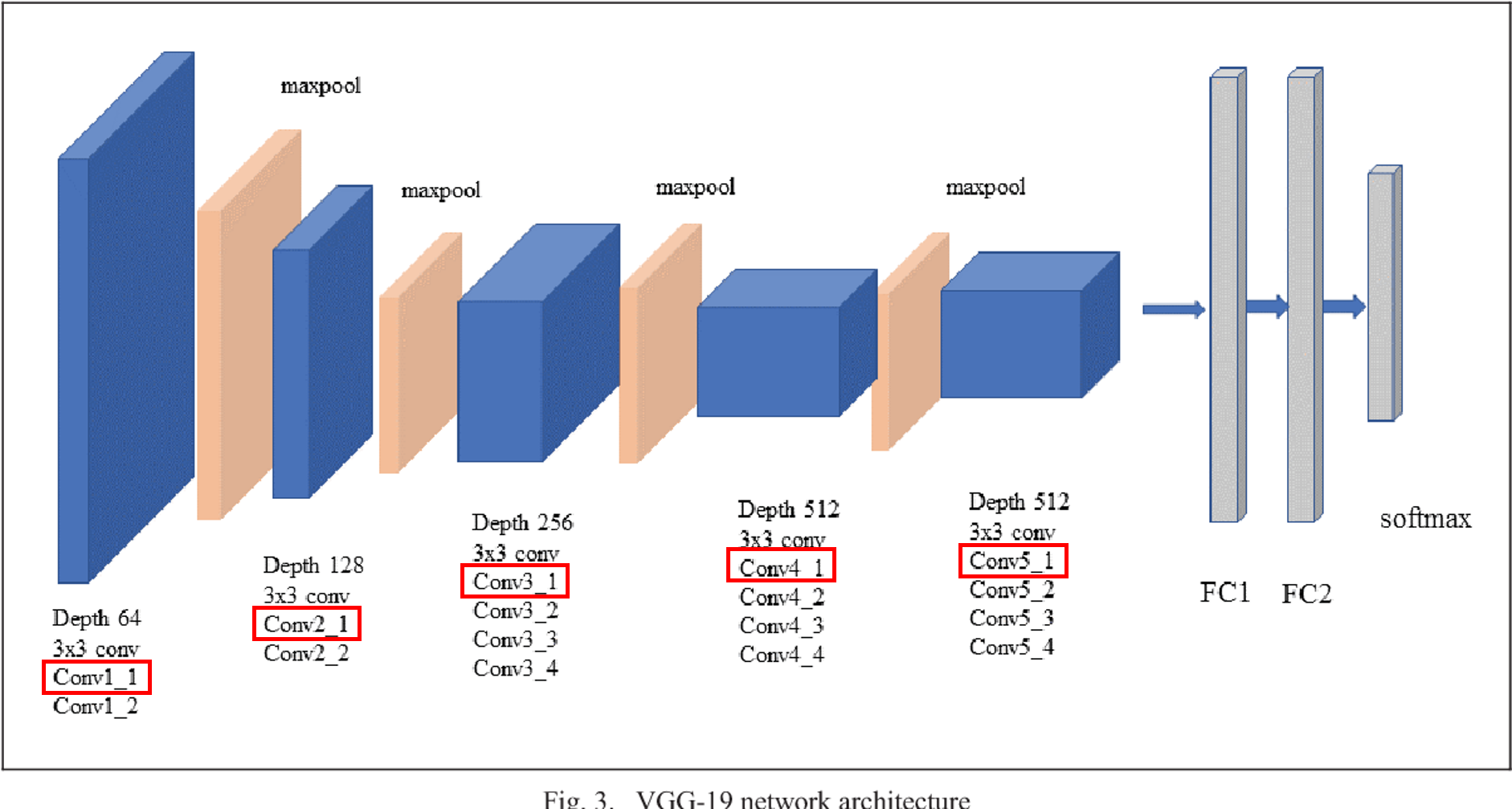
학습된 모델을 VGG19를 로드하여 추출할 대상이미지를 정하고, 입력이미지에 대해서 Loss function이 최소화하도록 만들어주어 추출한 특징을 시각화하였다. 여기서 VGG19 모델에서 특징을 추출하는 부분은 총 5개의 블록으로 구성되는데, "conv1_1, conv2_1, conv3_1, conv4_1, conv5_1" 에서 차례로 연산된 특징맵을 각각 시각화하였다.
이를 위해서 optimizer 는 LBFGS 방법을 사용하였으며, 입력인자로 Tensor형 입력이미지를 넣게되고 Loss를 Backward 함으로써 학습이 이루어지며 아래 코드로 요약하여 나타낼 수 있다.
input_img = torch.randn(content_img.data.size(), device=device) # Tensor형 노이즈를 입력이미지로 사용하여 추출특징을 시각화함
...
optimizer = optim.LBFGS([input_image.requires_grad_()]) # 입력이미지에 대해 Backpropagation 가능하도록 Gradient 를 활성화하고, 이를 최적화 대상으로 Optimizer에 입력함
...
loss.backward() # Loss의 값이 최소화가 되도록 Backward 하여 입력이미지값을 추출한 특징으로 Update 함4. 분석결과
4-1. Content Loss function
Content Loss는 아래와 같은 수식으로 입력이미지(F)와 대상이미지(P)의 픽셀단위의 차이를 뜻한다.
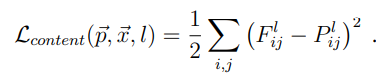
아래는 위의 Loss를 최소화하여 구한 각 레이어별 이미지이며, Loss가 단순히 픽셀간 비교이기 때문에 이미지에 큰 변화는 없다.

4-2. Style Loss function
Style Loss는 레이어 내부의 특징맵을 아래 수식의 Gram matrix(G) 를 이용하는데, 이는 특징맵을 벡터화하여 서로 내적하는 것으로 결국 입력이미지와 타겟이미지간의 Gram matrix 값을 비교하는 것이다.


해당 Loss 를 이용하면 레이어별로 다양한 특징을 추출할 수 있는데, 아래 결과를 보면 레이어를 통과할수록 특징이 단순한 색상표현에서 패턴으로 변화해가고 있는 것이 보인다.
이러한 Loss의 특성은 이미지 생성에 다양하게 적용될 수 있는데, 그 중 하나가 "Image Completion, Inpainting" 분야이다.

4-3. Extensions to Style Transfer
이 두 가지 Loss Functions에 적절한 가중치를 적용하면, 기존이미지에 스타일을 입힌 새로운 이미지를 생성할 수 있는데 청자켓 이미지에 위의 그림 스타일을 옮겼을 경우, 아래와 같은 결과가 나타난다. Content Loss는 레이어별 큰 차이가 없으므로, "A Neural Algorithm of Artistic Style"에서 나온대로 "Conv4_1"에서만 추출한 특징맵을 사용하였고 Style은 "Conv1_1, Conv2_1, Conv_3_1, Conv4_1, Conv5_1"에서 추출한 특징맵을 사용하였다.
가중치의 변경이나 학습 수, 스타일, 콘텐츠 이미지의 변경에 따라 매번 다르게 나타날 수 있는데, 기대했던 Style transfer 와는 다소 거리가 먼 결과물(?)이 나와서 제대로 구현한 건지 모르겠다.

5. 출처
- arxiv.org/abs/1508.06576 - A Neural Algorithm of Artistic Style
- pytorch.org/tutorials/advanced/neural_style_tutorial.html - NEURAL TRANSFER USING PYTORCH
'인공지능 > 컴퓨터비전' 카테고리의 다른 글
| Deep Learning Based 2D Human Pose Estimation: A Survey (2) | 2021.04.30 |
|---|---|
| Visual Interpretability for Convolutional Neural Networks (2) | 2021.04.22 |
| Convolution Neural Networks & Visualization (0) | 2021.04.21 |
| Loss functions for Image Transformation (1) | 2021.04.20 |
| EdgeConnect: Generative Image Inpainting with Adversarial Edge Learning (0) | 2021.04.19 |



